HTTP/1.1 vs HTTP/2 🔗
HTTP 프로토콜에 대해서는 관심이 없다가 문득 텔레그램의 봇을 통해 우연히 HTTP/2의 개념을 처음으로 접하게 되었다. 이 문서는 HTTP/1.1과 HTTP/2 의 차이점을 설명하고 1.1에서 2로 변화하면서 어떻게 개선되었는지 기술한다.
HTTP/1.1 동작 방식 🔗
HTTP(HyperText Transfer Protocol)은 웹에서 클라이언트(웹 브라우저)가 웹 서버(httpd, nginx, etc…)와 통신하기 위한 프로토콜 중 하나이다. HTTP 1.1은 클라이언트와 서버 간의 통신을 위해 다음과 같은 과정을 거친다.
위 그림에서 알 수 있듯이 HTTP/1.1은 기본적으로 Connection 한 개당 하나의 요청을 처리하도록 설계되어 있다. 이 때문에 동시에 여러개의 리소스를 주고받는 것이 불가능하고 요청과 응답이 위 그림처럼 순차적으로 이루어진다. 이런 설계 방식 때문에 HTTP 문서 내에 포함된 다수의 리소스 (image, css, script)를 처리하려면 요청할 리소스 개수에 비례하여 Latency(대기시간)이 길어진다.
그렇다면 이러한 순차적인 처리에 따른 지연 외에 또 다른 단점이 있는지 좀 더 살펴보자.
단점 1. HOL(Head Of Line) Blocking - 특정 응답의 지연 🔗
HTTP/1.1의 경우 HOL Blocking이 발생할 수 있다. HOL (Head-Of-Line) 블로킹이란 네트워크에서 같은 큐에 있는 패킷이 첫 번째 패킷에 의해 지연될 때 발생하는 성능 저하 현상을 말한다. 웹 환경에서의 HOL 블로킹은 패킷 처리 속도 지연 뿐만 아니라 최악의 경우 패킷 드랍까지 발생할 수 있다.
아래는 스위치에서 발생할 수 있는 HOL Blocking 현상이다.
보통의 스위치는 패킷을 받는 input, switching fabric, output 등 총 세 부분으로 구성된다. 그래서 패킷이 input으로 들어오면 switching fabric을 거쳐 output으로 도달하게 된다. 하지만 위의 예시처럼 첫 번째, 세 번째 입력이 동일한 인터페이스(Output 4)로 패킷을 보내려 하고 이에 switching fabric에서 세 번째 입력의 패킷을 먼저 처리해버리면 같은 클록 사이클 안에 첫번째 입력을 인터페이스로 보내지 못한다. 이렇게 순차적 처리와 output 스트림 제한으로 인한 블로킹 현상을 HOL Blocking이라 일컫는다.
웹 환경에서의 HOLB는 두 가지 종류가 있다. 첫 번째는 HTTP의 HOLB, 두 번째는 TCP의 HOLB이다. 먼저 HTTP 프로토콜에서 발생할 수 있는 HOLB에 대해 살펴보자.
HTTP에서의 Head-Of-Line Blocking 🔗
HTTP/1.1의 ‘Connection 하나 당 하나의 요청을 처리하는’ 방식을 개선할 수 있는 개선 방법 중 pipelining이라는 것이 존재한다. 이것은 하나의 connection을 통해 여러 개의 파일을 요청/응답할 수 있는 기법을 말하는데 이 기법을 통해 어느 정도의 성능 향상을 꾀할 수 있지만 한 가지 문제점이 있다. 아래 예시처럼 하나의 TCP 연결에서 3개의 이미지를 얻으려고 하는 경우 HTTP 요청 순서는 다음 그림과 같다.
| --- a.png --- |
| --- b.png --- |
| --- c.png --- |
순서대로 첫 번째 이미지를 요청하고 응답받고 두 번째, 세 번째도 마찬가지로 처리하는데 첫 번째 이미지의 응답 처리가 완료하기 전까지 b.png, c.png에 대한 요청은 대기하게 된다. 이와 같은 현상을 HTTP/1.1의 Head of Line Blocking이라 부르며 파이프 라이닝의 가장 큰 문제점 중 하나이다.
TCP에서의 Head-Of-Line Blocking 🔗
TCP에서의 HOLB는 HTML/2에서도 나타나는 단점으로서 TCP의 고질적인 문제이다. TCP의 경우 패킷 LOSS가 발생하면 패킷을 재전송하게 되는데 패킷 전송 후 상대방으로부터 ACK 신호를 받지 못하면 전송한 다음 번에 패킷들을 전송하지 않고 모두 대기 상태로 두고 이전에 보냈던 패킷을 재전송한다. 이러한 특성 때문에 TCP를 사용하게 될 경우 어쩔 수 없이 Head-Of-Line Blocking 문제가 발생하게 된다.
단점 2. RTT(Round Trip Time) 증가 🔗
HTTP/1.1의 경우 일반적으로 Connection 하나에 요청 한 개를 처리한다. 이렇다보니 매번 요청 별로 Connection을 만들게 되고 TCP 상에서 동작하는 HTTP의 특성상 3-way Handshake가 반복적으로 일어나며, 불필요한 RTT증가와 네트워크 지연을 초래하여 성능을 지연시킨다.
단점 3. 무거운 Header 구조 🔗
HTTP/1.1의 헤더에는 많은 메타 정보들이 저장되어 있다. 클라이언트가 서버로 보내는 HTTP 요청은 매 요청 때마다 중복된 헤더 값을 전송하게 되며 서버 도메인에 관련된 쿠키 정보도 헤더에 함께 포함되어 전송된다. 이러한 반복적인 헤더 전송, 쿠키 정보로 인한 헤더 크기 증가가 HTTP/1.1의 단점이다.
HTTP/1.1을 개선하기 위한 노력들 🔗
앞서 언급한 HTTP/1.1의 문제점들을 극복하는 몇 가지 트릭들이 있는데 그 중 참고 사이트에서 언급된 것들을 기술하겠다.
개선방법 1. Image Spriting 🔗
웹 페이지를 구성하는 다양한 아이콘 이미지 파일의 요청 횟수를 줄이기 위해 아이콘을 하나의 큰 이미지로 만든 다음 CSS에서 해당 이미지의 좌표 값을 지정하여 표시한다.

개선방법 2. Domain Sharding 🔗
요즘 브라우저들은 HTTP/1.1의 단점을 극복하기 위해 여러 개의 Connection을 생성해서 병렬로 요청을 보내기도 한다. 하지만 브라우저 별로 도메인당 Connection의 개수 제한이 존재하기 때문에 근본적인 해결책은 아니다.
개선방법 3. Minified CSS/Javascript 🔗
HTTP를 통해 전송되는 데이터의 용량을 줄이기 위해서 CSS, Javascript를 축소하여 적용한다. name.min.js, name.min.css 등이 그 예이다.
개선방법 4. Load Faster (옛 방식과 최신 방식) 🔗
이 방법은 브라우저에서 문서를 어떻게 빨리 로드하는가에 대한 정보들이다. 이러한 개선 방법으로 옛 방식과 최신 방식으로 나누어 설명할 수 있는데, 먼저 옛 방식으로 해결하는 방법부터 설명하겠다.
옛 방식은 스타일시트 파일을 HTML 문서의 상위에 배치하고 스크립트 파일을 HTML 문서 하단에 배치하는 방법으로 로드를 더 빨리 한다는 방법인데 이는 웹 브라우저가 페이지를 로드하는 방법과 관련이 있다.
아래는 브라우저가 <script> 태그가 포함된 페이지를 로드하는 과정을 간략하게 설명한 것이다.
- index.html과 같은 HTML 페이지를 가져온다. (fetch)
- 가져온 HTML 페이지를 파싱한다.
- 파서(parser)가
<script>태그를 만나면 해당 태그가 가리키고 있는 스크립트 파일을 요청한다. 이 때 파서는 스크립트 파일을 받아오는 동안 HTML 파싱을 멈추거나 블락한다. - 스크립트 파일이 모두 받아지면 파서는 파싱을 계속한다.
- HTML 파일의 남은 부분을 계속해서 파싱한다.
이러한 웹 브라우저의 접근 방법(스크립트 파일 수신 대기)은 스크립트 파일 내에서 DOM을 생성할 수 있는 가능성이 있기 때문인데 근래의 자바스크립트 개발자 대부분은 더이상 아래처럼 HTML 파일 로드 중에 자바스크립트를 이용해서 DOM을 생성하지 않는다. 하지만 브라우저 입장에서는 스크립트의 DOM 변경여부를 사전에 알 수 없기 때문에 스크립트 파일을 받아오는 동안 파싱을 멈출 수 밖에 없다.
document.addEventListener("DOMContentLoaded", function () {
document.getElementById("user-greeting").textContent = "Welcome!"
});
하지만 이러한 개선방법은 한 가지 문제점을 가지고 있는데, 전체 DOM을 파싱하기 전까지 스크립트 파일을 받아오지 못하는 단점이 있다. 한 예로, 옛날 ‘파병온라인’이라는 온라인 FPS 게임이 있었는데 당시 캐시 충전을 하는 페이지가 단순 웹페이지로 되어 있었다. 그리고 단순하게 오른쪽 마우스를 차단하는 방식으로만 페이지를 구성했는데 문제는 자바스크립트가 로드되는 시간을 늦추면(강제로 모뎀의 속도를 낮추면) 스크립트가 다운로드 되기 전에 페이지의 소스코드를 볼 수 있었다. 당시는 초등학생 때라 그러한 원리를 몰랐지만 이렇게 스크립트 배치와 브라우저의 파싱 방법에 대해 알고나니 당시의 문제점이 무엇인지 알게 되었다.
때문에 요즘에는 아래와 같은 방법으로 로드 문제를 해결한다.
async 🔗
<script type='text/javascript' src='path/to/s1.js' async></script>
<script type='text/javascript' src='path/to/s2.js' async></script>
이 속성(attribute)를 사용하면 스크립트 로드를 비동기적으로 받아오게 된다. 때문에 받아오는 동안 파싱을 블락하는 현상을 해결할 수 있다. http://caniuse.com/#feat=script-async 에 따르면 브라우저 중 94.57% 가 async 키워드를 지원한다.
defer 🔗
<script type='text/javascript' src='path/to/s1.js' defer></script>
<script type='text/javascript' src='path/to/s2.js' defer></script>
defer 속성은 순차적으로 실행된다(s1.js 파일이 먼저 로드되고 s2.js가 그 다음에 실행된다). 다만 defer 속성이 사용된 경우 브라우저의 파싱을 블락하지 않는다. 하지만 async 속성과 다르게 defer 스크립트들은 전체 문서가 로드된 후에 실행된다는 차이점이 있다.
최근 트렌드는 head 태그에 자바스크립트를 삽입하고 async 키워드나 defer 키워드를 사용하는 것이다.
개선방법 5. Data URI Scheme 🔗
이 방법은 HTML 문서 내에 이미지 리소스를 Base64로 인코딩된 이미지 데이터로 직접 기술하는 방법으로 이를 이용하여 서버로의 요청을 줄이는 방식이다.
구글의 SPDY 🔗
위에서 언급된 노력들도 근본적인 HTTP/1.1의 단점을 해결할 수 없었다. 그래서 구글은 더 빠른 웹을 실행하기 위해 Throughput 관점이 아닌 Latency 관점에서 HTTP를 고속화한 SPDY(스피디)라 불리는 새로운 프로토콜을 구현하였다. 다만 SPDY는 HTTP를 대체하는 프로토콜이 아니가 HTTP를 통한 전송을 재정의하는 형태로 구현되었다. 그리고 이 SPDY는 HTTP/2 초안의 참고 규격이 되게 된다.
HTTP/2 🔗
HTTP/2는 HTTP/1.1을 완전하게 재작성한 것이 아니라 프로토콜의 성능에 초점을 맞추어 수정한 버전이라 생각하면 된다. 특히 End-user가 느끼는 latency나 네트워크, 서버 리소스 사용량 등과 같은 성능 위주로 개선했다. 아래는 HTTP/2의 주요 특징들이다.
Multiplexed Streams 🔗
HTTP/2는 Multiplexed Streams를 이용하여 Connection 한 개로 동시에 여러 개의 메시지를 주고 받을 수 있으며 응답은 순서에 상관없이 Stream으로 주고 받는다. HTTP/1.1의 Connection Keep-Alive, Pipelining의 개선 버전이라 보면 된다.
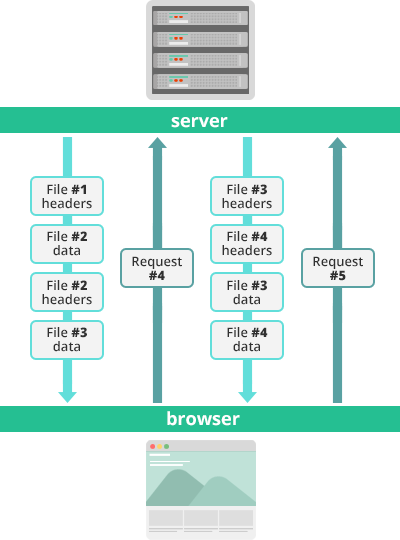
Stream Prioritization 🔗
문서 내에 CSS 파일 1개와 이미지 파일 2개가 존재하고 이를 클라이언트가 요청하는 상황에서, 이미지 파일보다 CSS 파일의 수신이 늦어진다면 브라우저 렌더링에 문제가 생기게 된다. HTTP/2에서는 이러한 상황을 고려하여 리소스 간의 의존관계에 따른 우선순위를 설정하여 리소스 로드 문제를 해결한다.
Server Push 🔗
서버는 클라이언트가 요청하지 않은 리소스를 사전에 푸쉬를 통해 전송할 수 있다. 이렇게 리소스 푸쉬가 가능해지면 클라이언트가 추후에 HTML 문서를 요청할 때 해당 문서 내의 리소스를 사전에 클라이언트에서 다운로드할 수 있도록 하여 클라이언트의 요청을 최소화할 수 있다.
Header Compression 🔗
HTTP/2는 헤더 정보를 압축하기 위해 Header Table과 Huffman Encoding 기법을 사용하여 처리하는데 이를 HPACK 압축방식이라 부르며 별도의 명세서(RFC 7531)로 관리하고 있다.
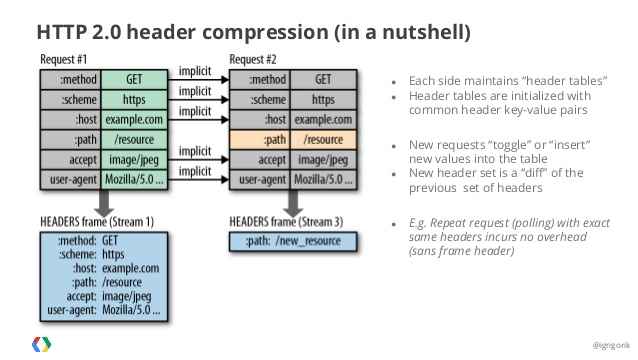
위 그림처럼 클라이언트가 요청을 두 번 보낸다고 가정할 때 HTTP/1.x의 경우 헤더 중복이 발생해도 중복 전송한다. 하지만 HTTP/2에서는 헤더에 중복이 있는 경우 Static/Dynamic Header Table 개념을 이용하여 중복을 검출해내고 해당 테이블에서의 index값 + 중복되지 않은 Header 정보를 Huffman Encoding 방식으로 인코딩한 데이터를 전송한다.
